NVIDIA Is Giving Away Free AI Inference — Here's How to Claim It
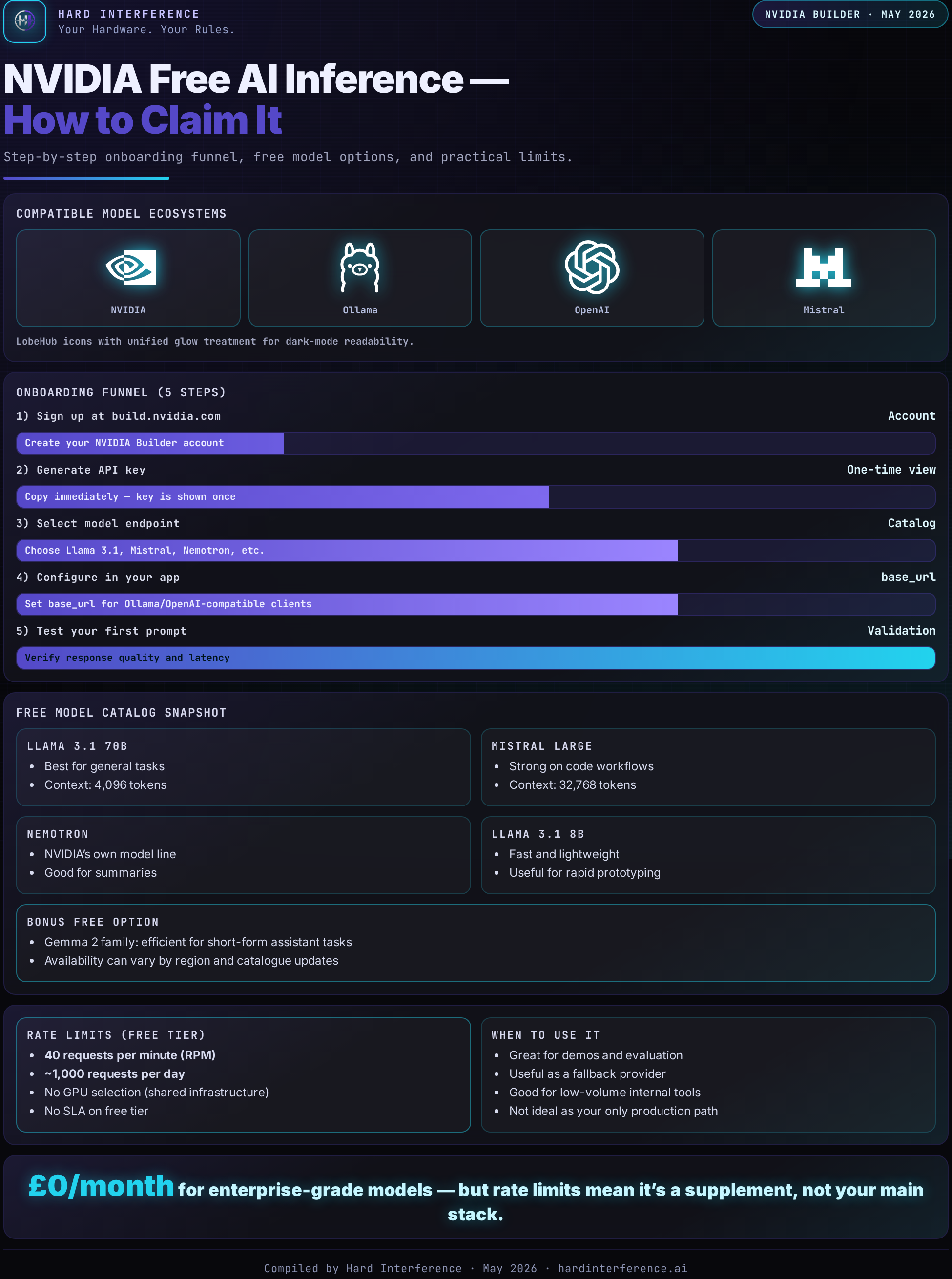
NVIDIA's build.nvidia.com offers free API access to 100+ models including Nemotron, GLM-5, DeepSeek, and Kimi-K2.5. No credit card required. Here's exactly how to get your key and plug it into your agent.
NVIDIA is quietly running the most generous free tier in AI right now, and half the people who should know about it don't.
build.nvidia.com gives you free API access to over 100 models — not just NVIDIA's own Nemotron family, but third-party models like GLM-5, MiniMax-M2.5, DeepSeek, and Kimi-K2.5. All hosted on NVIDIA's DGX Cloud infrastructure. All OpenAI-compatible. All free for development use.
This isn't a trial that expires in 14 days. It isn't a "first 100 requests free" teaser. It's a standing offer for anyone with an NVIDIA Developer account. Here's how to claim it.
What You Get
- 100+ models via OpenAI-compatible API endpoints
- NVIDIA Nemotron family: Nemotron-3-Super-120B, Nemotron-3-Nano-30B, and the newer vision models
- Third-party models: GLM-5, MiniMax-M2.5, DeepSeek-V3, Kimi-K2.5, and others NVIDIA is constantly adding
- Free API credits for hosted inference (rate-limited to ~40 RPM for personal accounts)
- Downloadable NIM containers for self-hosting, if you're an NVIDIA Developer Program member
- GPU sandbox instances — actual Blackwell and Hopper hardware accessible from your browser for benchmarking
The endpoint is https://integrate.api.nvidia.com/v1 — drop-in compatible with any OpenAI client library.
Step-by-Step: Get Your API Key
1. Create an NVIDIA Developer Account
Go to build.nvidia.com and click Sign In → Create Account.
You'll need:
- An email address
- Phone number for SMS verification (this is the step that trips some people up — NVIDIA is aggressive about bot prevention, and some regions have limited SMS support)
If SMS verification fails for your region, you can request manual verification on the NVIDIA Developer Forums.
2. Generate Your API Key
Once logged in:
- Click your profile → API Keys (or go directly to build.nvidia.com and look for the key generation button on any model page)
- Click Generate Key
- Copy the key immediately — it starts with
nvapi-
That's it. No credit card, no billing setup, no "upgrade to Pro" nag.
3. Enable Public API Endpoints
This is the gotcha that catches people. Your API key works out of the box for some models, but for others you need Public API Endpoints enabled on your organisation.
If you get a 403 Forbidden error when calling a model, it means your organisation hasn't been granted public endpoint access yet. The fix:
- Go to NVIDIA NGC → your organisation settings
- Look for the Public API Endpoints toggle and enable it
- If you don't see the option, post on the NVIDIA Developer Forums requesting it — the team typically enables it within 24 hours
This is the most common support thread on the NVIDIA forums right now. You're not alone if you hit this.
4. Test It
curl -s https://integrate.api.nvidia.com/v1/chat/completions \
-H "Authorization: Bearer nvapi-YOUR_KEY_HERE" \
-H "Content-Type: application/json" \
-d '{
"model": "nvidia/nemotron-3-super-120b-a12b",
"messages": [{"role": "user", "content": "Hello, are you free?"}],
"max_tokens": 100
}'
If you get a JSON response with tokens, you're in.
Plug It Into Hermes Agent
If you're running Hermes Agent, adding NVIDIA NIM as a provider is straightforward. In ~/.hermes/.env:
NVIDIA_API_KEY=nvapi-YOUR_KEY_HERE
In ~/.hermes/config.yaml:
providers:
nvidia-nim:
api: https://integrate.api.nvidia.com/v1
name: NVIDIA NIM
default_model: nvidia/nemotron-3-super-120b-a12b
Then check it's working:
hermes model # Select the nvidia-nim provider
hermes chat # Start chatting
The Rate Limit Reality
Free tier rate limits are real. Personal accounts get roughly 40 RPM (requests per minute) and 1,000 requests per day per model. For individual development and agent workflows, that's generous. For a production service or a heavily-used bot, you'll need to request a rate limit increase — which NVIDIA processes through their forums.
Some models (especially new releases) may have tighter limits during launch windows. The build.nvidia.com model pages show current rate limits for each model.
The Self-Hosting Option
If you're an NVIDIA Developer Program member (free to join), you also get access to downloadable NIM containers. This means you can run the same optimised models on your own GPU hardware:
# Pull and run a NIM container locally
docker run --gpus all \
-e NGC_API_KEY=nvapi-YOUR_KEY \
nvcr.io/nim/nvidia/nemotron-3-super-120b-a12b:latest
This is the Hard Interference play — free cloud inference for prototyping, self-hosted inference for production. Your hardware, your rules.
The Models Worth Trying
From the catalogue, these are the ones I'd recommend for agent workflows:
| Model | Why It Matters | Size |
|---|---|---|
| Nemotron-3-Super-120B | The flagship. Strong reasoning, good instruction following. Already used on OpenRouter free tier. | 120B (MoE) |
| Nemotron-Nano-30B | Faster, lighter. Good for high-volume tasks where 120B is overkill. | 30B |
| GLM-5 | Chinese-English bilingual. Strong on bilingual tasks. | Varies |
| DeepSeek-V3 | Excellent coding model. Competitive with closed-source on benchmarks. | 671B (MoE) |
| Kimi-K2.5 | Long-context specialist. Good for document-heavy workflows. | Varies |
| MiniMax-M2.5 | General purpose, solid multilingual support. | Varies |
The Catch (Because There's Always a Catch)
- SMS verification can fail — especially outside the US/UK/EU. Use the forums for manual verification requests.
- Public API Endpoints must be enabled — not automatic for every account. Check your org settings.
- Rate limits are real — 40 RPM / 1K daily is fine for development, not for production.
- Bot farms are a problem — NVIDIA is actively fighting abuse. If your usage pattern looks automated, you may get throttled or blocked. Use it for genuine development.
- Free credits can change — NVIDIA hasn't announced any plans to reduce the free tier, but it's worth checking the current limits periodically.
Why This Matters
The AI inference market is in a weird place right now. OpenRouter offers free model access but with tight rate limits. Cloud providers charge by the token. Local inference is free but requires GPU hardware. NVIDIA's NIM programme sits in the sweet spot: free cloud inference with real GPUs, no token charges, and a path to self-hosting when you're ready to own the stack.
For the Hard Interference approach — building with local hardware first, using cloud only when it genuinely helps — this is exactly the kind of resource that makes the economics work. Prototype on NVIDIA's nickel. Deploy on your own GPU. Same models, same API, same inference engine. Just different infrastructure.
The Pipeline — At a Glance
Found this useful? 👉 Follow @Raf_VRS for more AI Guides 👉 Support the work: ko-fi.com/rafvrs
#HardInterference #NVIDIA #NIM