Choosing the Right Models (So You Don't Burn Money)
Six local models on an RTX 5070 Ti showed why speed, quality, and routing matter more than benchmark bragging rights.
The benchmark
Within 24 hours of setting up, I needed data. Which models actually work on this hardware? What are the real speed/quality tradeoffs?
I built a standardized benchmark -- 5 test categories, each scored objectively:
- Simple Greeting -- Can it respond coherently and concisely?
- Thinking / Reflection -- Can it produce original, structured analysis?
- Logical Reasoning -- Can it solve a reasoning puzzle?
- Code Generation -- Can it write working Python?
- Math -- Can it solve and explain a math problem?
The results
| Model | Score (/10) | Avg Response | Best For |
|---|---|---|---|
| gemma4:e4b | 10 | 0.78s | Fast coding, tool orchestration, strict JSON |
| gpt-oss:20b | 10 | 0.89s | Fast coding, tool orchestration, strict JSON |
| qwen3.5:9b | 10 | 6.31s | Coding + structured outputs |
| gemma3:12b | 7 | 0.89s | General chat, quick drafts |
| glm-4.7-flash | 7 | 78.11s | Deep analysis only; NOT for agent loops |
| devstral-small-2 | 3 | 1.01s | Fallback / experimental only |
The model map — at a glance
Here's the benchmark logic as a visual routing map: which models were fast, which were useful, and which ones looked good until latency made them painful.
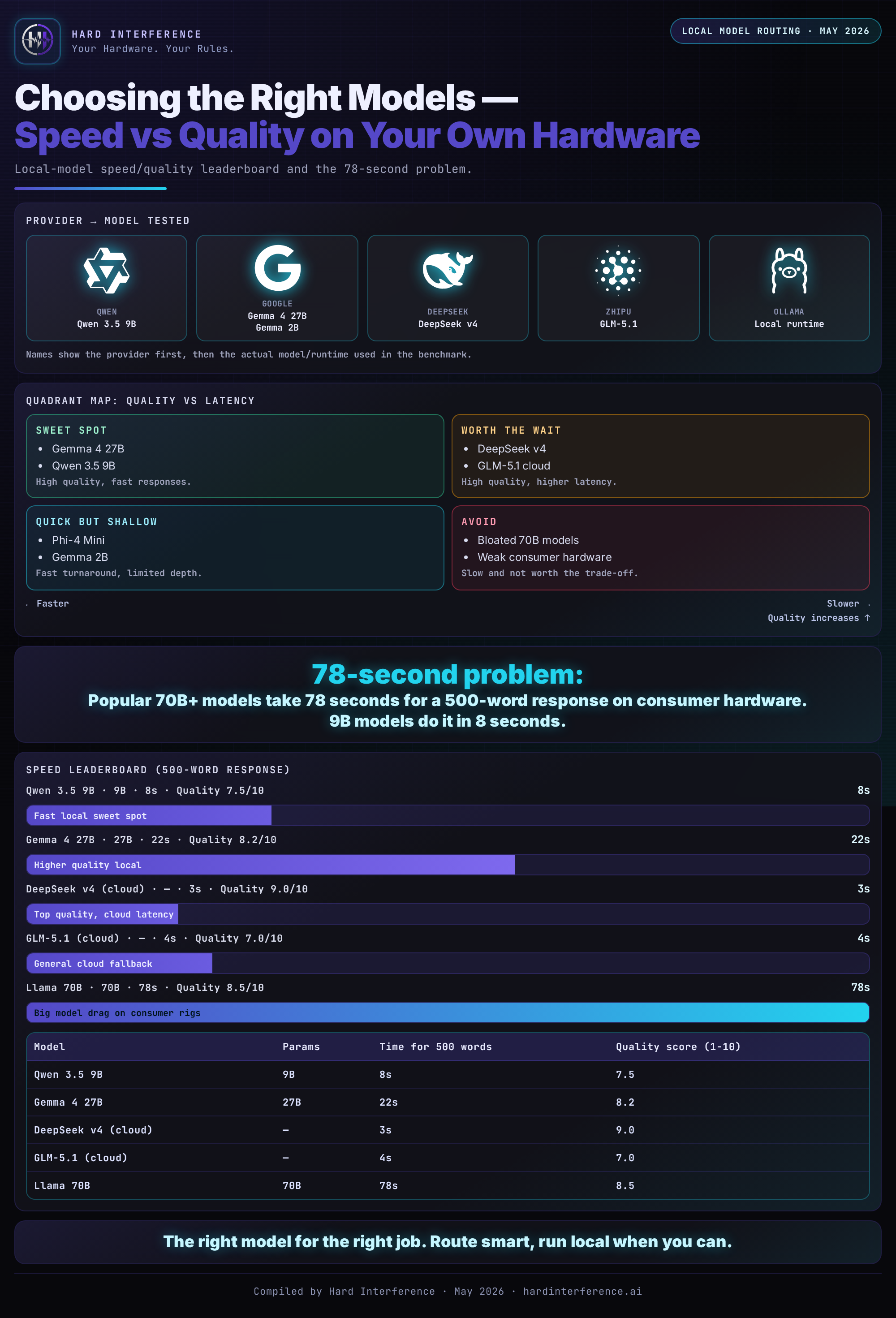
The 78-second problem
Look at that glm-4.7-flash number. 78 seconds. It scored 7/10 -- not bad quality-wise. But in an agent loop where you might make 20 API calls to solve a task? You're looking at 26 minutes per task. That's not an AI assistant, that's a pen pal.
Speed matters more than quality when you're building automated workflows.
The routing strategy
This benchmark directly shaped my model routing:
- Primary fast local:
gemma4:e4borgpt-oss:20b-- sub-second, 10/10 quality - Structured output backup:
qwen3.5:9b-- 6 seconds is fine for batch JSON work - Avoid in agent loops:
glm-4.7-flash-- quality is OK, latency kills it - Experimental:
devstral-small-2-- keep around, don't trust yet
The API discovery
One more critical finding: the Ollama /api/generate endpoint returns empty response fields for models that use "thinking tokens" (gemma4, qwen3.5). You have to use /api/chat with streaming to get both message.content and message.thinking properly separated.
This bug made my initial benchmarks look terrible -- models scoring 0/5 on categories they were actually handling fine, just through a different API field. Always verify your measurement tools before trusting the measurements.
Found this useful? 👉 Follow @Raf_VRS for more Build Journal updates 👉 Support the work: ko-fi.com/rafvrs #SelfHosting #AIAgents #HardInterference