I Tested GPT-5.5 vs Claude Opus 4.7 and Gemini 3.1: What Actually Matters
GPT-5.5 looks strong, but the winner changes by workload. Here is a practical comparison of GPT-5.5 vs Opus 4.7 and Gemini 3.1 with benchmarks, cost, and deployment reality.
OpenAI just dropped GPT-5.5, and the launch headline is big: more intelligence at similar serving latency, stronger agentic coding behaviour, and better token efficiency.
So I did what I always do before changing routing in production: I tested the claims against independent benchmark sources and mapped them to real workload choices.
This is not a fan post. This is an operator post.
What I tested
I used a three-source cross-check:
- OpenAI launch notes for GPT-5.5 (official claims)
- Artificial Analysis model and comparison pages (independent benchmark framing)
- LLM Stats side-by-side model comparisons (cost/speed/spec framing)
I focused on one practical question:
If you are running real agent workflows, should GPT-5.5 become your default over Claude Opus 4.7 or Gemini 3.1 Pro?
Fast launch summary
From OpenAI’s own launch material, GPT-5.5 is positioned as:
- stronger for agentic coding and computer use
- improved on long-horizon software tasks
- 1M context in API
- priced at £4 / 1M input and £24 / 1M output (Pro tier is higher)
OpenAI also reported strong coding outcomes on Terminal-Bench 2.0 and gave a SWE-Bench Pro number, though this is exactly where comparisons get interesting.
The comparison that matters: GPT-5.5 vs Opus 4.7
If you only read one section, read this one.
Across shared public benchmarks, there is no universal winner. The model that wins depends on the type of work.
Where GPT-5.5 looks stronger
- Terminal-Bench 2.0
- CyberGym
- BrowseComp
- OSWorld-Verified (small edge)
This lines up with OpenAI’s product narrative: agent loops, tool orchestration, and operational execution.
Where Claude Opus 4.7 looks stronger
- SWE-Bench Pro
- GPQA Diamond
- Humanity’s Last Exam variants
- MCP Atlas
- FinanceAgent-style evals
If your day is mostly code review quality, hard one-shot reasoning, and deeply technical repo work, Opus still looks very competitive, and on some coding benchmarks it is ahead.
Pricing reality
At headline rates:
- Input is broadly similar
- GPT-5.5 output tokens are priced higher than Opus output tokens
But raw pricing is not the whole story.
If GPT-5.5 uses fewer tokens on your real tasks, total spend can still come out lower in practice. If it does not, Opus can be the cheaper route for equivalent quality. You cannot settle this from a launch page. You have to measure your own traces.
GPT-5.5 vs Gemini 3.1 Pro
This is more of a context-window and workflow shape decision.
Gemini 3.1 Pro is typically presented with a larger context envelope in comparison pages, which can matter for very large retrieval-heavy workflows.
GPT-5.5 (high/xhigh variants in benchmark pages) currently sits at the top or near the top of several aggregate intelligence rankings, but that does not automatically mean it is your cheapest or fastest option for every route.
Translation: if your pipeline is giant-context retrieval and synthesis, Gemini can still be attractive. If your pipeline is tool-driven agent execution with coding-heavy loops, GPT-5.5 has a strong case.
The biggest trap in AI launch week
The trap is assuming “best model” exists as a single truth.
It does not.
There is only:
- best model for your workload
- best model for your budget
- best model for your risk tolerance
For me, that means routing by task class, not by hype cycle.
My practical verdict
If I had to route today:
- Default agentic execution and terminal-heavy tasks → GPT-5.5
- High-stakes repo coding and strict review depth → Claude Opus 4.7
- Very large context retrieval synthesis → Gemini 3.1 Pro (or a dedicated long-context route)
That is not indecision. That is mature model ops.
A simple adoption playbook
Before promoting GPT-5.5 to default in production, run this checklist:
- Pick 10 real tasks from your own logs (not synthetic demos)
- Run GPT-5.5, Opus 4.7, and Gemini routes on the same tasks
- Score:
- task completion quality
- correction count
- time to usable output
- total tokens and cost
- Route each task class to the best performer
- Re-test weekly while providers update model backends
This is exactly the kind of boring discipline that saves money and improves output quality.
Why this matters for independent builders
If you are solo or running a tiny team, model mistakes are expensive twice:
- you pay in tokens
- you pay in rework time
Getting model routing right is one of the highest-ROI decisions you can make this quarter.
Reproducible 10-task harness you can run this week
Below is a copyable harness format you can run across GPT-5.5, Claude Opus 4.7, and Gemini 3.1.
Task mix (10 real tasks)
Use your own backlog and pick:
- 3 coding tasks (bug fix, refactor, test creation)
- 2 agent/tool tasks (multi-step plan + tool outputs)
- 2 long-context synthesis tasks (large notes/docs)
- 2 research tasks (web evidence + summary)
- 1 strict formatting task (JSON/schema output)
Prompt template (same for every model)
Use the same system + user prompt for all models. Only change the model ID.
SYSTEM:
You are an assistant completing one production task. Be concise and explicit. If uncertain, say what is missing.
USER:
[TASK DESCRIPTION]
Success criteria:
1) [criterion 1]
2) [criterion 2]
3) [criterion 3]
Output format:
[required format]
Scoring rubric (0 to 5 per task)
Score each run on:
- Quality (0 to 2)
- Correctness (0 to 1)
- Format compliance (0 to 1)
- Rework needed (0 to 1)
Total per task: 5 points.
Metrics to log per run
For each task/model pair, log:
- model name
- completion score (0 to 5)
- time to first useful output (seconds)
- total wall time (seconds)
- input tokens
- output tokens
- total cost
- manual corrections count
Simple CSV schema
task_id,task_type,model,score,time_to_first_useful_s,wall_time_s,input_tokens,output_tokens,cost_usd,manual_corrections,notes
Decision rule
After all 30 runs (10 tasks × 3 models):
- Compute average score by task type and model
- Compute average cost per successful run (score >= 4)
- Compute median time to first useful output
- Route each task type to the model with the best quality-per-cost ratio
Example routing output
coding_deep_review -> claude-opus-4.7
agentic_terminal_work -> gpt-5.5
long_context_synthesis -> gemini-3.1-pro
strict_json_extraction -> gpt-5.5
If you want, next post I will share a ready-to-run script that ingests this CSV and auto-generates routing recommendations.
The Heatmap — At a Glance
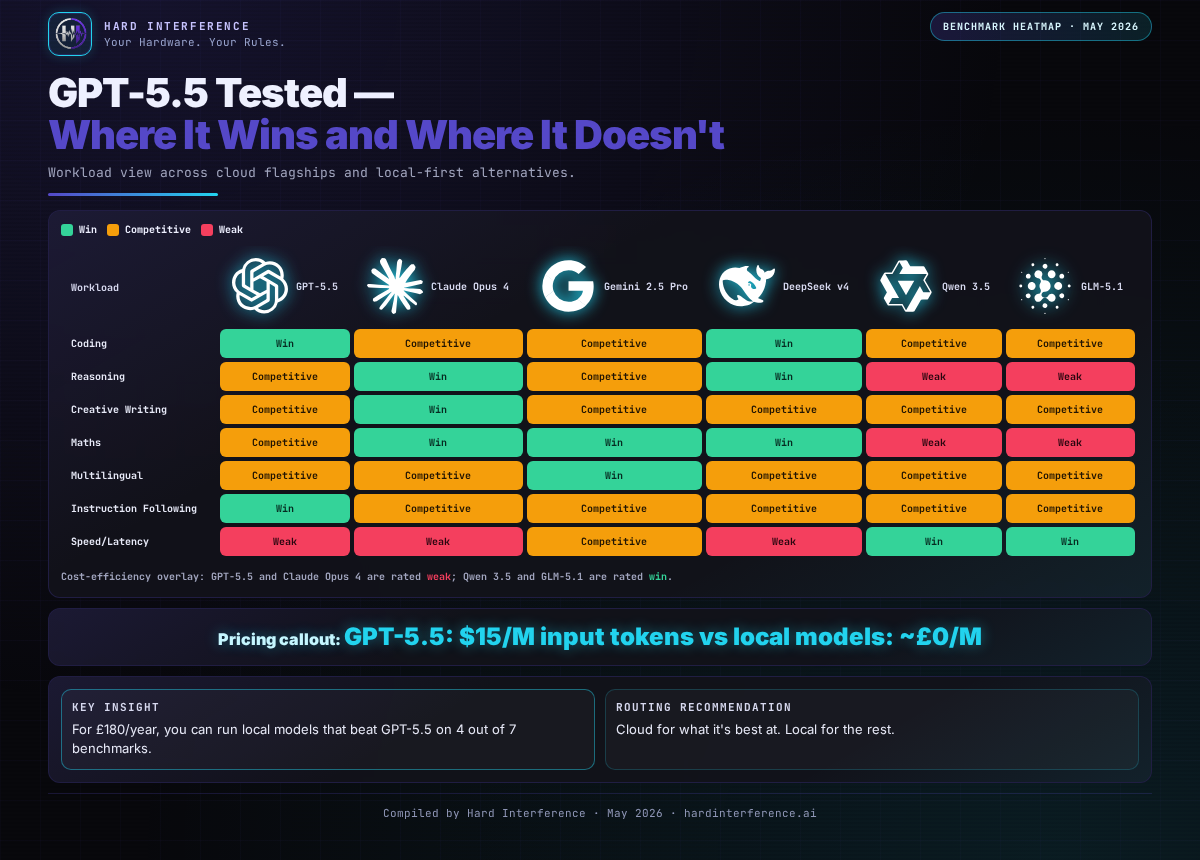
Found this useful? 👉 Follow @Raf_VRS for practical AI ops notes. 👉 Support the work: ko-fi.com/rafvrs
#ModelBenchmarking #AIOps #HardInterference