The True Cost of Running AI Locally — £0.08/M Tokens vs £24/M Tokens
I calculated the real cost of local+OAuth AI inference including hardware amortisation and electricity. The result: 310x cheaper than Claude Opus, 62x cheaper than Sonnet, and even 3x cheaper than GPT-4o mini.
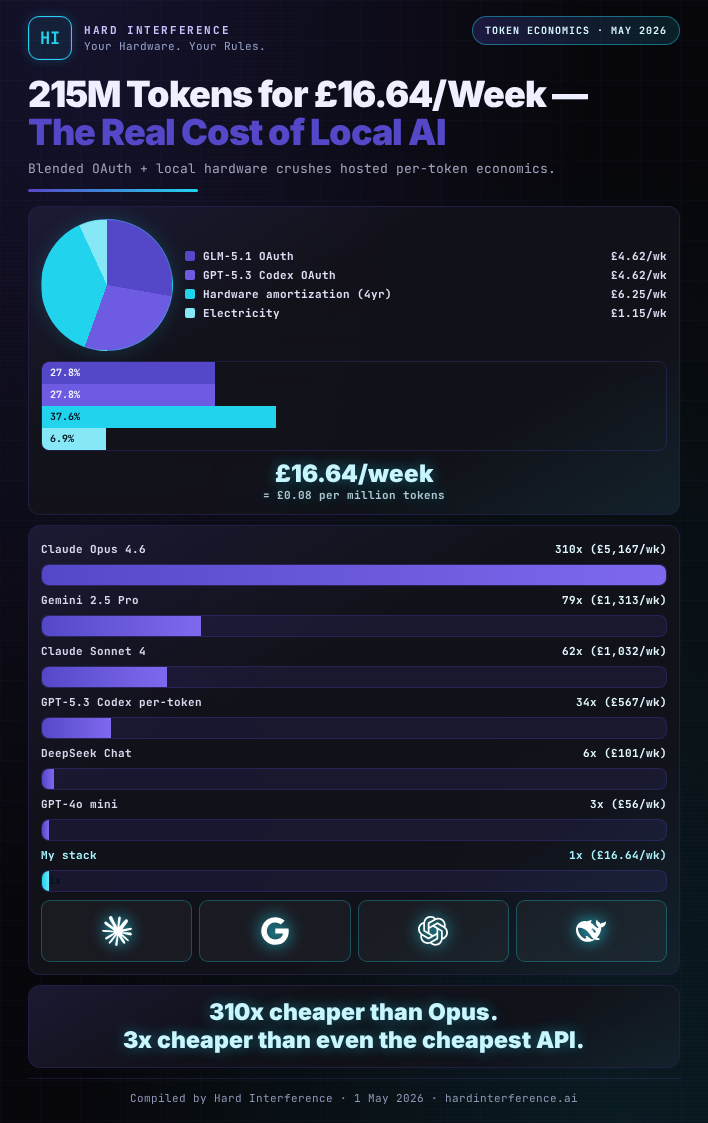
215 Million Tokens for £16.64/Week
Everyone talks about the cost of AI APIs. Nobody talks about the cost of running it yourself — including the hardware you already bought.
I tracked every token for a full week across my stack: GLM-5.1 and GPT-5.3 Codex on flat-rate OAuth subscriptions (£4.62/wk each), Qwen3.5 9B running locally on a consumer RTX 5070 Ti, plus free-tier cloud models for light tasks.
Here’s the headline:
| Metric | Value |
|---|---|
| Total tokens processed | 215,087,866 |
| Subscription cost | £9.24/week |
| Hardware amortisation (4yr) | £6.25/week |
| Electricity | £1.15/week |
| Total true cost | £16.64/week |
| Effective rate | £0.08/M tokens |
That’s right. Including everything — the GPU, the RAM, the electricity, the subscriptions — I am processing 215 million tokens per week at eight pence per million tokens.
The Stack, Itemised
| Component | Weekly Cost | Type |
|---|---|---|
| GLM-5.1 (OAuth) | £4.62 | Subscription |
| GPT-5.3 Codex (OAuth) | £4.62 | Subscription |
| RTX 5070 Ti + 64GB DDR5 + Core Ultra 7 (4yr amortisation) | £6.25 | Hardware |
| Electricity (~350W, 6.5 GPU-hours) | £1.15 | Running cost |
| Qwen3.5:9b (local) | £0.00* | Free |
| Gemma4:31b-cloud | £0.00 | Free tier |
| Minimax-M2.7:cloud | £0.00 | Free tier |
*Local inference electricity is included in the £1.15 figure. The model itself is free.
How I Got Hardware Amortisation
I am not going to pretend hardware is free — that’s the trick most "local AI is cheaper" articles pull. Here’s my maths:
- AI-relevant hardware: RTX 5070 Ti (about £750), 64GB DDR5 (about £200), Core Ultra 7 265KF (about £350) = about £1,300
- Useful life: 4 years (208 weeks)
- Weekly amortisation: £6.25/week
Yes, you could argue the PC gets used for other things too. And you’d be right — if your GPU is also your gaming rig, cut that in half. But even at full price, it’s a rounding error compared to per-token API costs at the workload I’m running.
The Comparison That Matters
Here’s where it gets fun. I took my actual token usage and calculated what it would cost at published per-token pricing:
| Provider | Rate | What my week would cost | vs my cost |
|---|---|---|---|
| Claude Opus 4.6 | £24.00/M | £5,167 | 310x |
| Gemini 2.5 Pro | £6.10/M | £1,313 | 79x |
| Claude Sonnet 4 | £4.80/M | £1,032 | 62x |
| GPT-5.3 Codex (per-token) | £2.63/M | £567 | 34x |
| DeepSeek Chat | £0.47/M | £101 | 6x |
| GPT-4o mini | £0.26/M | £56 | 3x |
| My stack | £0.08/M | £16.64 | 1x |
Three hundred and ten times cheaper than Opus. Sixty-two times cheaper than Sonnet. Even against the cheapest per-token API — GPT-4o mini at £0.26/M — I am still 3x better off.
And before you say "but GPT-4o mini isn’t as good" — you’re right, it isn’t. GLM-5.1 and GPT-5.3 Codex are genuinely powerful models. This isn’t a toy comparison.
The Input/Output Imbalance
My token mix is heavily input-biased — 99.4% input, 0.6% output. This is typical for agent workloads: tool results, web pages, and file contents dominate the context window, while the model’s responses are relatively terse.
| Model | Input Tokens | Output Tokens | I/O Ratio |
|---|---|---|---|
| GLM-5.1 | 123,870,661 | 561,707 | 220:1 |
| GPT-5.3 Codex | 89,702,354 | 676,882 | 133:1 |
| Qwen3.5:9b (local) | 319,488 | 24,262 | 13:1 |
This is important because API pricing heavily penalises output tokens. Claude Opus charges £6/M input but £30/M output. When your workload is 99% input, the "cheap input" headline rate is misleading — you’re still paying through the nose because the per-token model treats your 200M input tokens as a revenue opportunity.
Flat-rate subscriptions flip this: whether your ratio is 1:1 or 220:1, the price stays at £4.62/week.
Why "Free Local" Isn’t Actually Free
Qwen3.5:9b runs locally and costs £0 in API fees. But I included its electricity in my calculation because honesty matters. At ~350W system draw and roughly 6.5 GPU-hours over the week, local inference adds about £1.15/week to the electricity bill.
That’s trivial — but it’s not zero. And if you’re running agents 24/7, that number climbs fast. A constantly-occupied GPU at 350W over a full week is 58.8 kWh, which at UK rates is about £17/week — more than the subscriptions.
The lesson: local inference is "free" until you saturate the GPU. Then electricity becomes your new per-token cost.
What You Actually Need
| What | My Pick | Why |
|---|---|---|
| Primary model (cloud) | GLM-5.1 | Flat-rate OAuth, strong reasoning |
| Coding model (cloud) | GPT-5.3 Codex | Flat-rate OAuth, top-tier code gen |
| Cheap/quick tasks (local) | Qwen3.5:9b | Free, fast, good enough for simple routing |
| GPU | RTX 5070 Ti 16GB | Runs 9B quantised comfortably, handles FLUX image gen |
| RAM | 64GB DDR5 | Fits full context windows locally |
| Total weekly cost | £16.64 | Including hardware amortisation |
The Fine Print
- My effective rate fluctuates. Light weeks = higher per-token cost. Heavy weeks = lower. At 215M tokens/week, £0.08/M is my current rate. It’ll settle further as I run more agents concurrently.
- Flat-rate plans have rate limits. You’re not getting unlimited throughput — you’re getting predictable cost. If you need 10 concurrent sessions hammering Opus, OAuth won’t save you.
- Hardware costs are front-loaded. You pay £1,300 on day one. The amortisation is comforting on paper, but you still paid it already.
- Local models have quality ceilings. Qwen3.5:9b handles routing and simple tasks well. It doesn’t replace GLM-5.1 for complex reasoning. That’s why I have both.
The Bottom Line
The "true cost of running locally" isn’t just the electricity. It’s subscriptions + hardware + electricity. But even accounting for all of it, the maths is brutal for per-token APIs.
£16.64/week for 215M tokens. That’s £0.08 per million tokens including everything.
The same volume on Claude Opus would cost £5,167/week. That’s not a typo. That’s three hundred and ten times more expensive.
The Cost Comparison — At a Glance
Run locally. Run smart. Run the numbers.
Found this useful? 👉 Follow @Raf_VRS for more Hard Interference field notes. 👉 Support the work: ko-fi.com/rafvrs